I’ve noticed a welcome uptick in users saving Wikipedia articles to poketto.me recently.
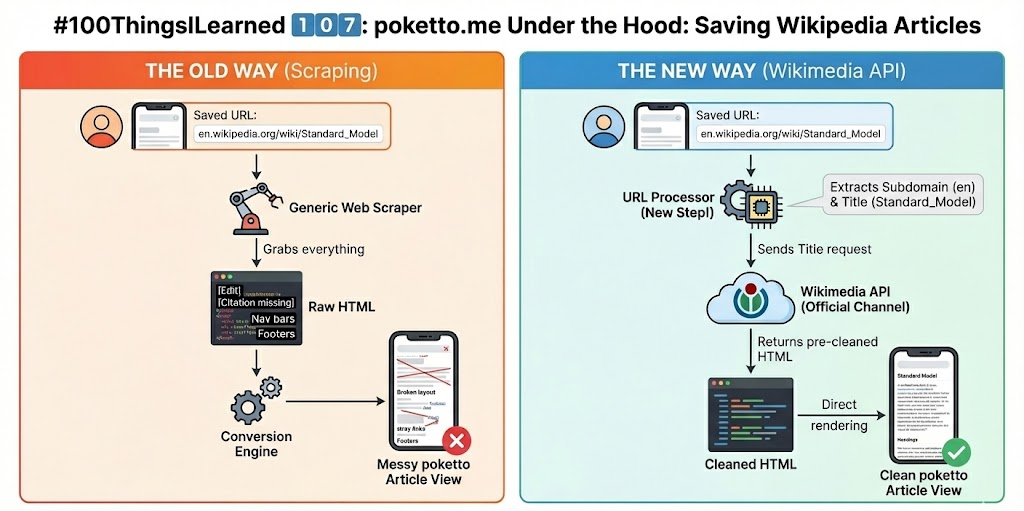
But until now, the app treated Wikipedia just like any other website: it scraped the raw HTML. Turns out, for Wikipedia, that is far from ideal:
🤯 Artifacts: The extracted content often included UI clutter like “Edit” buttons, navigation links, and “Citation missing” tags.
📋 Rendering issues: The standard HTML → Markdown → HTML conversion pipeline introduced plenty of ugly formatting glitches specific to wikis.
🌎 Bad citizenship: The Wikimedia Foundation actively discourages scraping. They encourage developers to access their data through official channels.
So, I investigated their API, and honestly? It's a much better solution.
🔎 Through the API, poketto.me now accesses the “clean” HTML content of any article directly, bypassing messy scraping and conversion.
🚧 The rate limits on the free tier are quite generous too: 5,000 on-demand requests per month.
The engineering hurdle: The only minor challenge was that users save URLs, but the Wikimedia API requires searching by article title.
The fix? poketto.me now first extracts the title and respective subdomain directly from the saved URL. It then uses those details to query the API for the clean content.
The experience for the user remains exactly the same, but the quality of the saved article is significantly better. Plus, I’m doing Jimmy Wales a favour by sticking to the official rules. 😃