Parliamentary inquiries have an interesting quality. Often, the same question is asked multiple times, either of different government ministers (“How much does your ministry spend on newspaper advertising?”, “How much yours?”, …) or with slight variations (“How much financial aid did NGO X receive?”, “How much financial aid did NGO Y receive?”, and so on). However, parliament treats each such inquiry as a separate entity with no link to its relatives. I thought it would be useful to group together “similar” inquiries, for example to show users how many unique questions were raised in a given timeframe or to later allow cross-inquiry analyses for similar inquiries.
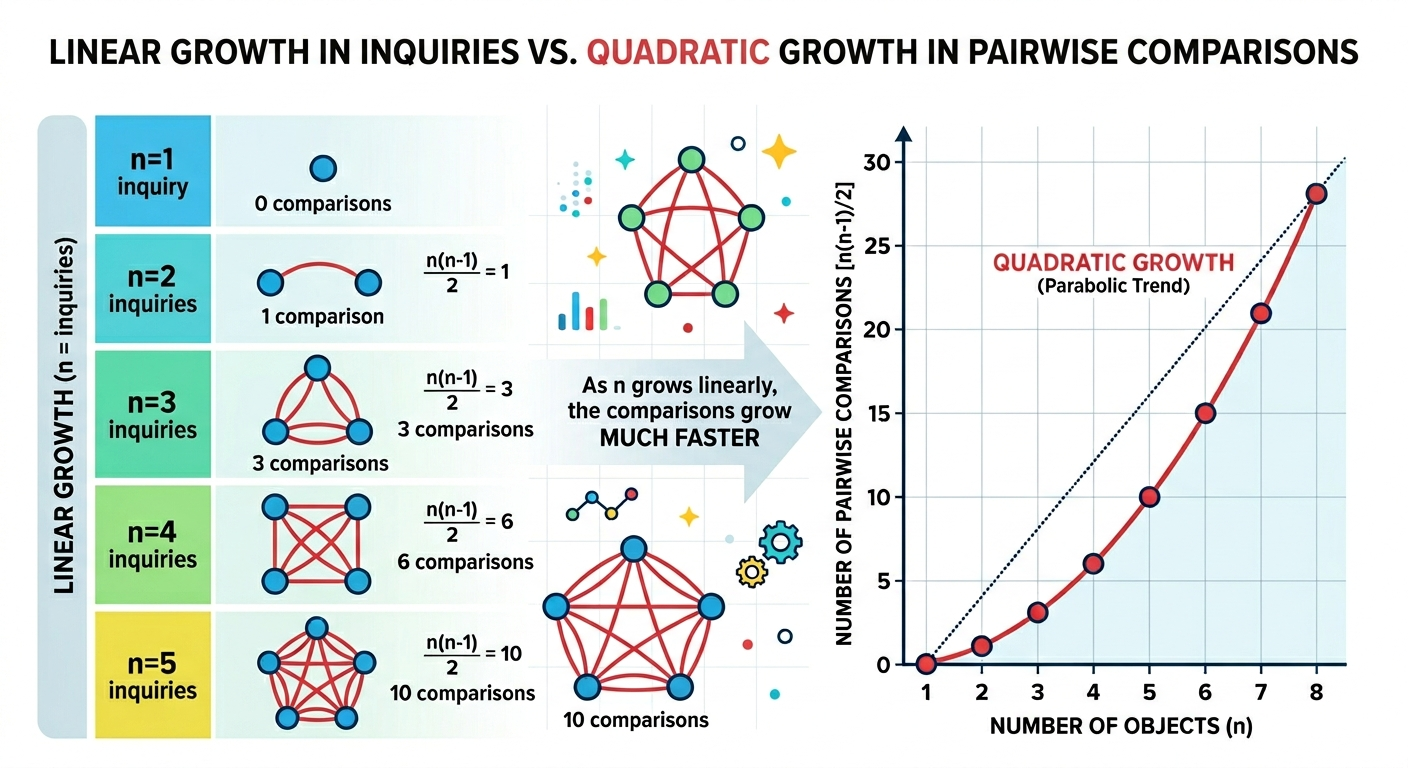
The problem: computing similarity requires pairwise comparisons. Even for the current parliamentary period, which began only 14 months ago, more than 5,000 inquiries have already been raised. Thus, my tool would have to perform 25 million comparisons just to get to the baseline! With an average of 10 new questions per day, that’s an additional 50,000 comparisons every day.
The solution: Let the database take care of it!
- Rather than performing any similarity matching in my own code, I use the pg_trgm text similarity module from Postgres, which is based on a simple trigram analysis. It’s as simple to use as:
SELECT similarity('Are we similar?', 'How similar are we?')
This returns a value of .78, indicating that these two strings are “pretty similar.” But on its own, that doesn’t solve my problem since I can hardly do a SELECT similarity(q1.title, q1.title) for 25 million pairs of inquiries, can I?
- So, to first ensure quick processing, I’ve added an index to my inquiries table to automatically store the trigrams:
CREATE INDEX idx_titles_trgm ON inqueries USING GIN (title gin_trgm_ops);
- Next, I created a helper table that stores the similarity of all existing inquiries. Unfortunately, populating this table does require the 25 million comparisons. But since it runs on the database, it’s pretty fast. And I only need to run it exactly once:
INSERT INTO similar_titles
SELECT a.id, b.id, similarity(a.title, b.title)
FROM inqueries a
JOIN inqueries b
ON a.id < b.id
AND a.title % b.title;
- After running this, I can quickly already generate a list of similar inquiries for any inquiry as fast as any other
SELECTstatement:
SELECT
y.id, y.title, ... s.similarity
FROM similar_titles s
JOIN inqueries y ON y.id = s.id_b
WHERE s.id_a = p_id
UNION ALL
SELECT
y.id, y.title, ... s.similarity
FROM similar_titles s
JOIN inqueries y ON y.id = s.id_a
WHERE s.id_b = p_id
ORDER BY similarity DESC;
- Finally, I’ve got to update the similar titles table for the new queries that get inserted every day. Fortunately, that’s as easy as initially populating it but a lot faster. Note that I wrapped this into a function that receives a list of IDs (
p_ids) as an input parameter:
INSERT INTO similar_titles (id_a, id_b, similarity)
SELECT q1.id, q2.id, similarity(q1.title, q2.title)
FROM inqueries q1
JOIN inqueries q2
ON q1.title % q2.title
AND q1.id != q2.id
AND q1.id < q2.id
WHERE q1.id = ANY(p_ids)
AND q2.id != ALL(p_ids)
UNION ALL
SELECT q1.id, q2.id, similarity(q1.title, q2.title)
FROM inqueries q1
JOIN inqueries q2
ON q1.title % q2.title
AND q1.id < q2.id
WHERE q1.id = ANY(p_ids)
AND q2.id = ANY(p_ids)
Similarity matching is fast, reliable, and scalable. Bonus: No need to write a single line of code since it’s all running on the database.
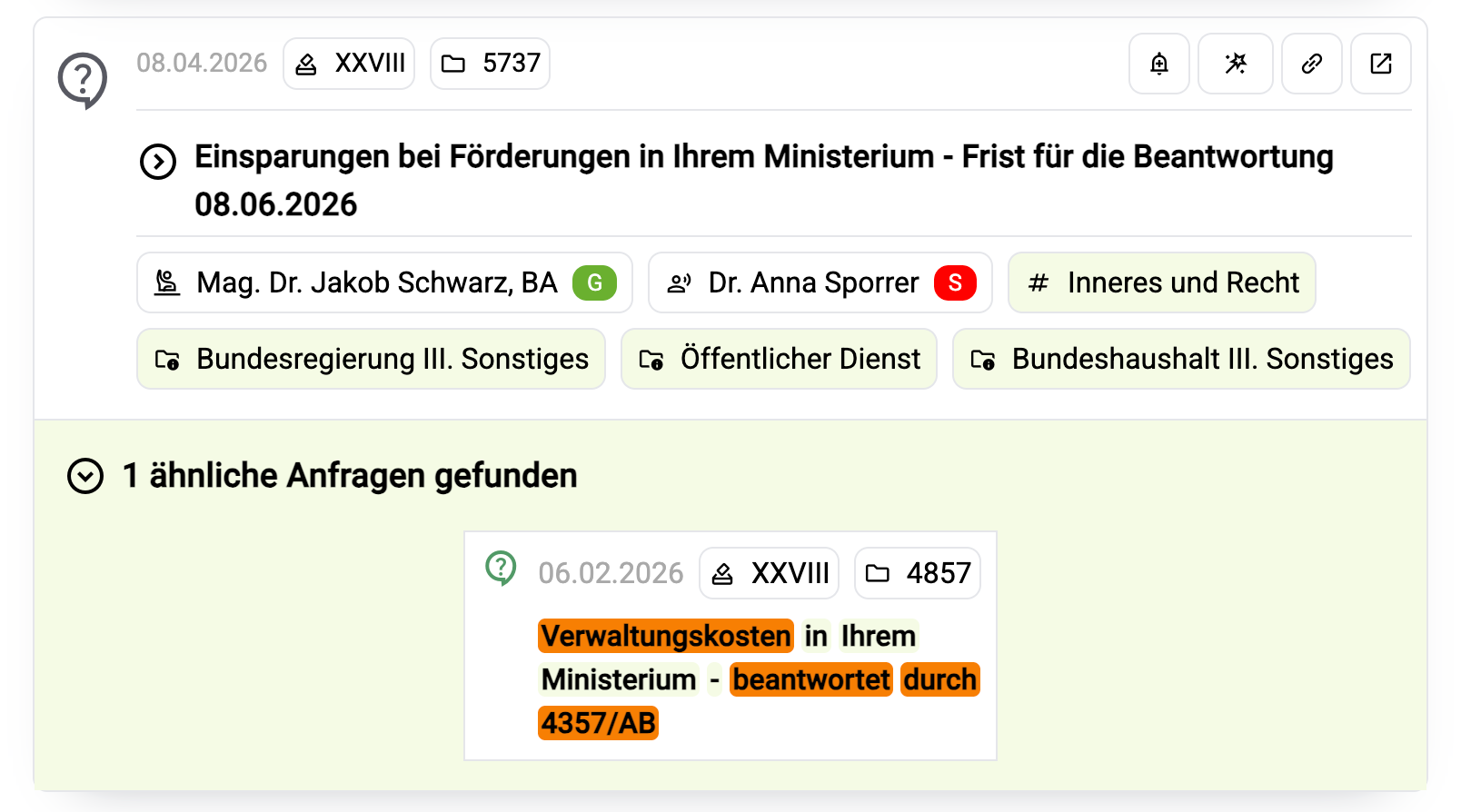
Here’s an example of what it looks like in practice: For this inquiry (“Einsparungen in Ihrem Ministerium”), another one (“Verwaltungskosten in Ihrem Ministerium”) is considered similar. Why? Because there’s one trigram that matches exactly (“in Ihrem Ministerium”):